Términos, conceptos y explicaciones básicas sobre el DNA como almacenamiento y transmisión de información pueden facilitar la lectura de este dossier para un lector no especializado.
INTRODUCCIÓN
Este artículo intenta transmitir al lector una información básica y general sobre los conceptos básicos del DNA y la transmisión de la información. Puede resultar algo denso en información, pero no debe olvidarse que se ha intentado simplificar al máximo, dentro de lo posible, por lo que algunos puntos, desde la perspectiva del especialista, parecerán muy incompletos.
Se trata, por otro lado, de un tema muy actual, con una ingente bibliografía y numerosísimas investigaciones en curso. Sugerimos al lector especialista que prescinda de estas páginas informativas y al no especialista que no intente recordar toda la información que aquí se presenta, sino sólo extraer una idea básica, para la mejor comprensión del resto de la información que se presenta. Reconocemos la necesidad de ser paciente en la lectura, aunque pretendemos que todo se vaya aclarando a medida que avanza el texto.
La remisión a la bibliografía de consulta, para ampliar conocimientos, es aquí inevitable.
GENERALIDADES
La materia orgánica está formada por cuatro componentes fundamentales cuya estructura química es distinta:
1) Glúcidos o hidratos de carbono: son los azúcares.
2) Lípidos o grasas.
3) Proteínas cuyas unidades elementales son los aminoácidos (aa), que forman las proteínas.
4) Acidos nucleicos (AN: DNA y RNA) formados por nucleótidos.
Nuestra misión es aclarar lo fundamental sobre los aa y, sobre todo, los A.N.
1. LOS AMINOACIDOS (aa)
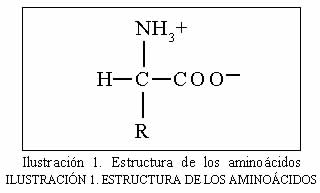
Son los componentes elementales de las proteínas. Tienen también otras funciones, que aquí no nos preocupan. Los veinte aminoácidos (1) que forman las proteínas tienen en común en su estructura que, en el mismo átomo de carbono (C) están unidos un grupo carboxilo (-COOH) y un grupo amino (-NH2), mientras que se diferencian en la naturaleza del resto R.
Los aminoácidos se unen entre sí por la reacción del grupo carboxilo de uno con el grupo amino del otro. Este enlace se llama peptídico y el resultado es que se forma un dipéptido.
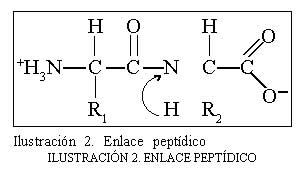
La importancia de los enlaces peptídicos quedará inmediatamente de manifiesto, cuando digamos que por unión de muchos aminoácidos por enlaces peptídicos se forman las proteínas.
La cadena peptídica adopta un aspecto tridimensional característico que depende del tipo de proteína, es decir, de la secuencia de aminoácidos de ésta. Gracias a esa estructura tridimensional, que se mantiene por enlaces entre los aminoácidos y fuerzas eléctricas, la proteína puede cumplir su función, que es muy variada. Hay varios niveles de estructura:
1) Estructura primaria. Es la cadena peptídica, es decir, la secuencia de aminoácidos que es específica para cada proteína.
2) Estructura secundaria. Es la posición relativa en el espacio de dos aminoácidos consecutivos o muy próximos. Puede ser de dos tipos:
a) -hélice, similar a una escalera de caracol (v. figura 3).
b) Hoja ß-plegada.
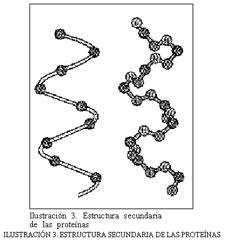
3) Estructura terciaria. Es la posición relativa en el espacio de dos aminoácidos alejados. Se produce al plegarse la -hélice y se mantiene por fuerzas eléctricas, enlaces débiles de hidrógeno y enlaces fuertes de sulfuro.
4) Estructura cuaternaria. Se produce por la interacción de distintas unidades terciarias entre sí. Para este tipo de estructura es necesario que la proteína esté formada por varias cadenas peptídicas.
FUNCIÓN
Las proteínas son las estructuras fundamentales para las funciones vitales del individuo. Estas funciones se llevan a cabo gracias a su estructura, la cual depende de su secuencia de aminoácidos. Podemos compararla con una cadena de letras, que formarán una palabra u otra según como se ordenen: La combinación P, A, T, A permitirá formar PATA, TAPA, APTA, como palabras españolas. Si una de las letras cambia, cambian también las palabras que pueden formarse: así, si tenemos P, A, S, O podremos formar PASO, ASPO, SAPO, POSA, SOPA, como palabras españolas igualmente.
En general, las proteínas se clasifican en dos grupos, las estructurales y las reguladoras. A las proteínas estructurales pertenecen el colágeno, la queratina (es decir, las que forman la piel, el pelo, las uñas), mientras que en las reguladoras tenemos en primer lugar las enzimas, que cumplen funciones metabólicas, como la digestión, la respiración celular, transformación de unos elementos en otros, degradación de sustancias. Hay otras proteínas reguladoras que cumplen más funciones, como las hormonas, las encargadas de transportar el oxígeno (hemoglobina), la contracción muscular, los canales de membrana, para la entrada y salida de sustancias de la célula.
2. LOS ÍCIDOS NUCLEICOS (A.N.)
Son moléculas orgánicas de estructura compleja. Cada A.N. está formado por tres componentes:
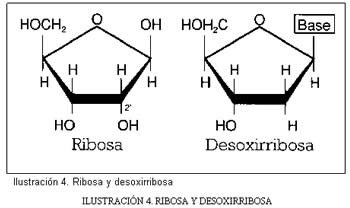
a) Un azúcar de cinco átomos de carbono. El azúcar que contienen los nucleótidos es esencial pues permite dividirlos en las dos clases que serán fundamentales para nosotros:
RNA: ácido ribonucleico, su azúcar es la ribosa.
DNA: ácido desoxirribonucleico, su azúcar es la desoxirribosa.
Ribosa y desoxirribosa se diferencian en su segundo átomo de carbono (C2):
b) Un resto de ácido fosfórico (P) (H3PO4) que se une al quinto carbono (C5) del azúcar.
c) Una base nitrogenada, que se une al primer carbono del azúcar (C1).
Hay cinco bases nitrogenadas que, según su estructura química, se dividen en dos subgrupos, bases púricas y bases pirimidínicas.
1. Bases púricas: están formadas por la condensación de dos ciclos de carbono y nitrógeno. Se ilustran a continuación a título informativo:
Para el DNA y el RNA nos interesa saber que hay dos bases púricas, la adenina y la guanina, que se encuentran en ambos.
2. Bases pirimidínicas: están formadas por un solo ciclo de carbono y nitrógeno. Hay tres bases pirimidínicas, la citosina se encuentra en DNA y RNA, la timina se encuentra sólo en DNA y el uracilo sólo en RNA.
La unión de un azúcar con un resto fosfórico (P) y una base forma un nucleótido. Según las bases que los componen se originan los nucleótidos correspondientes:
DNA
con Adenina – A
con Guanina – G
con Citosina – C
con Timina – T
RNA
con – A
con – G
con – C
con – Uracilo (U)
Los nucleótidos se pueden unir entre sí formando cadenas, pero esta unión siempre ha de ser entre nucleótidos de igual tipo, nunca pueden unirse desoxirribonucleótidos con ribonucleótidos. La unión se realiza a través de los grupos (P) que se unen al C3 del azúcar. Este enlace se llama enlace fosfodiéster.
Estamos ahora en condiciones de comprender la estructura de los ácidos nucleicos y sus diferencias:
El RNA está formado por un azúcar, la ribosa, y una base N, de tipo A,G,C,U. Se forman cadenas de RNA por enlaces fosfodiéster, con el resultado de cadenas simples, por lo cual se dice que son moléculas monocatenarias. Como veremos a lo largo de esta exposición, hay tres tipos de RNA por su función y localización:
– RNA mensajero (RNAm)
– RNA ribosomal (RNAr)
– RNA transferente (RNAt)
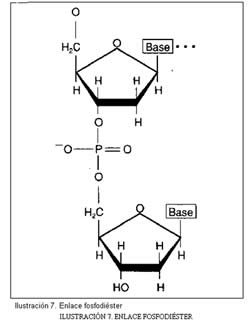
El DNA está formado también por un azúcar, la desoxirribosa, y una base N, esta vez de tipo A, G, C, T. Ahora bien, las cadenas de DNA, a diferencia de las de RNA, pueden ser simples o dobles, por lo que tenemos que esbozar una clasificación más compleja:
1. Por cadena
1.1 simple:
1.1.1 lineal _______
1.1.2 circular
1.2 doble:
1.2.1 lineal
1.2.2 circular
2. Por origen
2.1 nuclear (eucariotas)
2.2 mitocondrial
2.3 bacteriano (procariota)
2.4 viral
Para entender esta clasificación ahora hay que hablar de la estructura del DNA.
3. ESTRUCTURA DEL DNA
El DNA contiene la información genética, es decir, la información que define una especie y, dentro de ésta, incluso las características de cada individuo en particular. Para responder a la pregunta de cómo se consigue esto debemos decir que el DNA es un código, contiene la información para la síntesis de las proteínas, o sea, su secuencia de aminoácidos. Las proteínas son las que realizan las funciones de la célula y mantienen su estructura.
Hemos visto que el DNA puede encontrarse en unas organelas del citoplasma de las células eucariotas, las mitocondrias, de gran importancia para la reconstrucción de la historia genética de una especie, pero que principalmente se encuentra en el núcleo, donde es bicatenario, es decir, está formado por dos cadenas complementarias. Esta complementariedad consiste en que las bases nitrogenadas de las dos cadenas se emparejan según un patrón fijo: siempre una base púrica con una pirimidínica y siempre A – T, G – C. (Recordemos que en el DNA no hay U).
La unión entre las dos cadenas es por enlaces débiles de hidrógeno entre las bases (complementarias) de esas dos cadenas, por ejemplo:
1a cadena: A T T C G A G C T C C
enlaces
2a cadena: T A A G C T C G A G G
Gracias a lo que vimos anteriormente nos es fácil ahora comprender que la unión sea entre una purina y una pirimidina, las bases pirimidínicas tienen un solo ciclo, mientras que las purinas combinan dos ciclos. Si se pudiesen unir las bases indistintamente entre sí, la distancia entre las dos cadenas de DNA podría llegar a ser muy variable (Fig. 8).
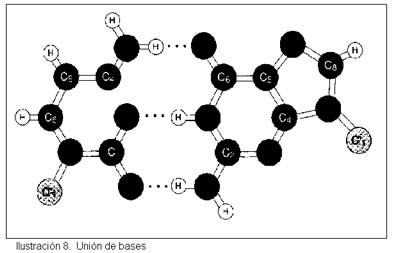
Al unirse siempre una purina y una pirimidina, la distancia entre las dos cadenas es siempre constante. Que la unión sea siempre A – T, C – G tiene una base química más complicada, que no es necesario conocer.
Las dos cadenas de DNA se enrollan y forman una doble hélice, llamada hélice de DNA, parecida a una escalera de caracol, que se puede representar esquemáticamente como en la figura 9.
4. CÉLULAS Y VIRUS
La célula puede ser de dos tipos, procariotas, (pro ‘ante’ y carion ‘núcleo’, es decir, sin núcleo verdadero) que sólo tienen un compartimento, y eucariotas.
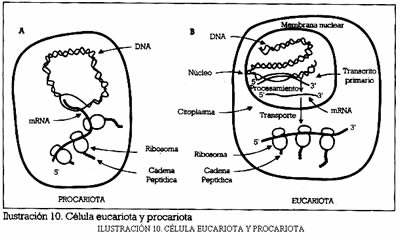
Las procariotas son las bacterias, que en su único compartimento tienen todos los orgánulos, los órganos minúsculos de las células, necesarias para el funcionamiento de las mismas, además del material genético, el DNA.
Las eucariotas forman seres unicelulares (como las amebas) y pluricelulares. Se diferencian de las procariotas en que tienen núcleo verdadero, separado del citoplasma por una membrana.
En el citoplasma están los orgánulos u organelas, de las que destacaremos los ribosomas, que tienen dos subunidades de distinto tamaño o peso molecular. Podríamos decir que son la mesa donde se sintetizan las proteínas y están formados por proteínas y RNAr.
El núcleo contiene en cambio el DNA, el material genético. Está separado del citoplasma por una membrana con poros y dentro de sí puede tener una zona más densa, llamada nucleolo, donde se sintetizan los ribosomas.
El DNA no sólo se encuentra en el núcleo de las eucariotas, en su citoplasma también hay unas organelas, las mitocondrias, que también contienen DNA.
Los virus tienen características especiales. Para replicarse (es decir multiplicarse o reproducirse) necesitan introducirse en una célula. Su material genético es variable, pues puede ser RNA de cadena doble o simple o DNA también de cadena doble o simple. Los virus sólo tienen un tipo de ácido nucleico, DNA o RNA, que está envuelto por una cubierta de proteínas. La posible variedad de su material genético da lugar a una compleja clasificación, de la que sólo tomaremos los llamados retrovirus, cuyo material genético es RNA y que contienen una proteína (un enzima) especial que copia el RNA en DNA, la transcriptasa inversa, cuyo descubrimiento supuso una revolución en el campo de la ingeniería genética. El virus del SIDA, HIV, es un retrovirus, por ejemplo.
A partir de los cuatro componentes fundamentales, con estructura química diferenciada, de la materia orgánica, azúcares, grasas, proteínas y ácidos nucleicos, se forman estructuras complejas combinables, hasta llegar a la vida, que se encuentra en la célula. Parte de ese material es genético, DNA, que es uno de los ácidos nucleicos junto con el RNA.
5. EL CÓDIGO GENÉTICO
Hemos dicho que el DNA almacena la información. Para responder a la pregunta de cómo lo hace se han presentado muchas hipótesis, que han llevado finalmente a la conclusión de que la información del DNA reside en la secuencia de bases de los nucleótidos, de modo paralelo a como las proteínas quedan definidas por su secuencia de aminoácidos. Este paralelismo es la base del código genético.
El primer problema que se presenta es que hay veinte aminoácidos y sólo cuatro bases distintas en el DNA. Una secuencia de tres bases o nucleótidos (es decir, un codón o triplete) codifican un aminoácido. Por matemática (combinaciones de cuatro elementos tomados de tres en tres) se puede comprobar que tenemos 64 codones o tripletes, es decir, sesenta y cuatro conjuntos de tres bases, que codifican sólo veinte aminoácidos, lo cual se explica porque hay más de un codón por cada aminoácido. Además de los codones para aminoácidos, hay codones de terminación como por ejemplo TAA, TAG y TGA. Es como un diccionario bilingüe: la parte de los ácidos nucleicos estaría en el núcleo y la de las proteínas en el citoplasma, hay que traducir desde los ácidos nucleicos a las proteínas usando ese diccionario, que es el código genético.
Un concepto fundamental, puesto que hablamos de códigos, es el de transcripción.
Hemos visto que el DNA contiene la información para la síntesis de proteínas. También sabemos que en la célula eucariota hay dos compartimentos, el núcleo con el DNA y el citoplasma. En el citoplasma es donde están los ribosomas y donde se sintetizan las proteínas. Ahora bien, si el DNA no puede salir del núcleo, hemos de preguntarnos cómo llega la información genética al citoplasma, donde debe ser leída e interpretada de modo que la síntesis de proteínas sea correcta. La respuesta está en la transcripción.
La transcripción es la copia del material genético del DNA que se codifica en una molécula de RNA complementario a ese DNA para sintetizar una proteína. El DNA copia en un RNA complementario el material genético que contiene el código que logrará la síntesis de una proteína. El trozo de DNA que codifica para sintetizar una proteína es un gen. La complementariedad entre el DNA y el RNA donde se copia el material genético se establece también entre las bases, con la diferencia de que en el RNA hay uracilo en vez de timina. Las columnas de complementariedad son, por tanto éstas:
DNA A C T G
RNA U G A C
Esta molécula de RNA que se forma es RNA mensajero (RNAm) y sale del núcleo a través de los poros que existen en la membrana nuclear, para llegar así al citoplasma. El mecanismo bioquímico por el que se forma una cadena de RNAm es complejo.
Primero, las dos cadenas del DNA que forman la -hélice han de separarse, lo que se consigue gracias a una enzima: la RNA polimerasa dependiente de DNA, que reconoce una secuencia especial en el DNA, «la región promotora» a la que se une esta enzima. La enzima va recorriendo el DNA (como una rueda en un raíl) y lo va copiando en una cadena de RNA complementario. Al llegar al final del gen, como habíamos llamado al trozo de DNA que contiene el código para sintetizar una proteína, se libera la enzima y se libera asimismo la nueva cadena de RNA. La cadena de RNAm sufre unas transformaciones necesarias para aumentar su estabilidad y pasa al citoplasma.
Los otros dos tipos de RNA (ribosomal y transferente) también se fabrican por este proceso, pero cumplen funciones distintas. Ya hemos tenido ocasión de decir que el RNA ribosoma (RNAr) forma parte de los ribosomas, la función del RNA transferente (RNAt) la veremos un poco más adelante.
6. TRADUCCIÓN
Una vez que el RNAm está en el citoplasma, va a los ribosomas y se sitúa entre las dos subunidades, la unión entre el ribosoma y el RNAm está próxima al triplete de iniciación del RNAm. En los ribosomas se lee este RNAm como un código, hay que traducirlo del idioma de los ácidos nucleicos al idioma de las proteínas.
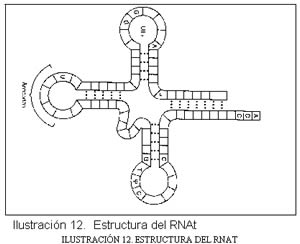
Los aminoácidos están libres en el citoplasma celular. Este es el momento en el que entra en escena el RNAt. El RNAt tiene una estructura especial, en su cadena hay secuencias de bases complementarias y, al plegarse la cadena se forman enlaces entre estas bases de manera que el RNAt adquiere una forma similar, esquemáticamente, a un trébol. Gracias a una enzima llamada aminoacil-RNAt sintetasa, que reconoce un aminoácido determinado y un RNAt determinado y de la que hay más de veinte tipos distintos (al menos uno por aminoácido), se produce la unión entre el aminoácido y el RNAt, se trata de una unión específica, no fortuita ni aleatoria, que forma una molécula: aa-RNAt.
Todos los RNAt tienen una secuencia especial llamada ANTICODON (triplete nucleotídico), que es complementaria del CODON del RNAm. Como hemos visto previamente, cada codón codifica para un aminoácido o también puede codificar para inicio o terminación.
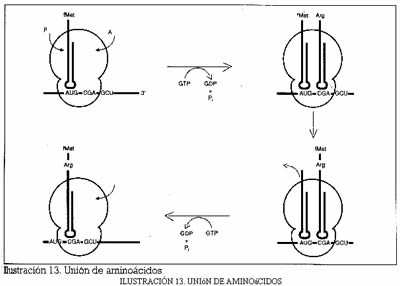
Los aminoácidos-RNAt van hacia el ribosoma en el que se está leyendo el RNAm y se unen ordenadamente al codón correspondiente a su anticodón. Al unirse el segundo aa-RNAt se forma un enlace peptídico entre los dos aminoácidos, se libera el primer RNAt y los dos aminoácidos quedan unidos al segundo RNAt. Cuando llega el tercer aa-RNAt se forma un enlace peptídico entre el segundo y el tercer aminoácido y se libera el segundo RNAt y así sucesivamente, hasta que se forma la cadena peptídica completa, que queda unida al último RNAt. Finalmente, se libera la cadena peptídica que formará la proteína.
El RNAm es leído por varios ribosomas al mismo tiempo, de manera que de un RNAm salen muchas proteínas del tipo que codifica.
Gracias a todos estos mecanismos se garantiza una proteína correcta y funcional. Si se alterase alguno de ellos, la proteína no sería buena y no podría funcionar, con el consiguiente transtorno para el individuo.

7. EXPRESIÓN GÉNICA
Todas las células de un organismo contienen la misma información genética (el mismo DNA); pero todos podemos comprobar fácilmente que no todas las células son iguales: por ejemplo, una célula de la piel es distinta a una célula del hígado o del hueso o muscular.
Si tienen todas la misma información, ¿cómo es que son distintas? Es por la diferente expresión génica en las distintas celulas: se copian distintos genes, con lo que se producen proteínas distintas, así que las células tienen funciones y características distintas.
En cuanto a cómo se controla la expresión génica, podemos decir, de modo muy resumido, que hay distintos factores:
1. Factores represores: son proteínas que se unen al DNA e impiden la acción de la RNA polimerasa dependiente de DNA.
2. Factores atenuantes: se han estudiado en genes de proteínas relacionadas con la producción de aminoácidos. El ejemplo más típico es el de la vía del Trp, que tiene una secuencia inicial que produce un RNAm el cual, al transcribirse, produce una proteína que necesita el aminoácido Trp. Cuando el Trp es abundante se puede producir esta proteína, que hace que se detenga la RNA polimerasa que está transcribiendo esos genes de proteínas para la producción de Trp.
3. Factores activadores: son proteínas que se unen cerca de la región promotora y facilitan la unión de la RNA polimerasa al DNA.
8. REPLICACIÓN Y TRANSMISIÓN DEL DNA
La replicación del DNA es la duplicación de este DNA. Con ello se obtienen dos ejemplares (original y copia) de la información genética. Para lograrlo se separan las dos cadenas de DNA y, gracias a una enzima especial, la DNA polimerasa, se produce una nueva cadena complementaria para cada cadena de DNA original.
Esta replicación es necesaria para la división de la célula. De esta manera, las dos células resultantes tienen la misma información genética, como sucede con las células de la piel, por ejemplo, que se están dividiendo continuamente.
A veces se producen errores en la replicación (se pone un nucleótido no complementario), hablamos entonces de mutaciones. A consecuencia de las mutaciones puede llegar a alterarse la proteína que codifica ese gen.
Por ejemplo, si TTC muta a TTT no se altera la proteína, porque los dos codones codifican para Phe, pero si TTC muta a CTC cambia Phe por leu, se altera la proteína y no funciona normalmente.
Unas pocas de estas mutaciones pueden haber sido beneficiosas para el individuo, se han perpetuado y han constituido la base de la evolución.
9. TRANSMISIÓN DE LA INFORMACIÓN GENÍTICA
La transmisión de la información genética de padres a hijos implica la existencia de organismos con reproducción sexual. Participan dos individuos en la producción de uno nuevo. Si las células que produjesen este nuevo individuo fueran como el resto de las células, las células del nuevo ser tendrían el doble de información genética que las células de sus padres. Ya sabemos que esto no es así.
Esquemáticamente intentaremos explicar ahora cómo se conserva la cantidad de información genética de unos individuos en otros.
En condiciones normales, las células del individuo contienen la información genética por duplicado, o sea, dos ejemplares de DNA, original y copia. Este DNA se va enrollando y enrollando junto con proteínas para formar los cromosomas. En la especie humana hay 46 cromosomas, dos de los cuales son cromosomas sexuales:
XX en la mujer
XY en el varón
Los cuarenta y cuatro cromosomas restantes se llaman autosomas.
En realidad, hay 23 parejas de cromosomas, 22 de autosomas y un par de cromosomas sexuales. La información genética está por duplicado y hablamos de células diploides.
Las células que van a producir los gametos (óvulos y espermatozoides) sufren un tipo de división especial, la meiosis. Las células resultantes de este tipo de división tienen la mitad de información genética que la célula madre, sólo hay veintitrés cromosomas (veintidós autosomas y un cromosoma sexual, siempre X en el óvulo y X o Y en el espermatozoide. Los gametos, por tanto, son células haploides, con sólo una copia del DNA.
Por la fusión de dos células haploides, en la fecundación, se forma una nueva célula diploide, el cigoto. Este cigoto tendrá, por lo tanto, veintidós pares de autosomas, de los que la mitad son de la madre y la otra mitad del padre, un par de cromosomas sexuales, el X del óvulo materno y un X o un Y del espermatozoide paterno. Es el espermatozoide, por tanto, el que determina el sexo del nuevo ser. El cigoto ya se divide normalmente, por mitosis, no por meiosis, con lo que las células hijas conservan un mismo número de cromosomas que la célula madre. Se forma así, por diferenciación celular, gracias a la distinta expresión génica, el nuevo ser con sus diferentes órganos. Las mitocondrias que se transmiten son sólamente las maternas.
LA INVESTIGACIÓN EN INGENIERÍA GENÉTICA
Cuanto más complejo es un organismo necesita mayor cantidad de DNA para codificar esta complejidad. Cuanto más DNA haya, será más difícil su estudio. Por ello en ingeniería genética se usan fundamentalmente las bacterias, ya que son organismos vivos relativamente sencillos y, además, al ser procariotas (es decir, el DNA está en el citoplasma) es más fácil la introducción de DNA (sólo tiene que atravesar la membrana de la bacteria) y también es más fácil su obtención. También puede añadirse que las bacterias son capaces de hacer muchas copias de pequeños fragmentos de DNA circulares, plásmidos, que son los usados normalmente en investigación.
10. CLONACIÓN
La clonación es el proceso por el que se obtienen un gran número de copias de un fragmento de DNA que nos interesa (normalmente un gen). Hay muchas técnicas diferentes de clonación. En general consiste en introducir (gracias a distintos métodos) el gen que nos interesa en la bacteria. Este gen se incorpora a algún plásmido que existe habitualmente en la bacteria y ésta lo copia por los procedimientos bioquímicos naturales. Posteriormente se rompen las bacterias y se purifica el gen, del que habrá muchas copias.
TÉCNICA PCR (POLIMERASA CHAIN REACTION)
Consiste en la amplificación del DNA. Se basa en que la enzima polimerasa, para copiar el DNA, necesita que existan unas pequeñas cadenas de nucleótidos, complementarias al inicio del fragmento que va a copiar. La polimerasa se une aquí y desde aquí continúa copiando. Esquemáticamentte, el método consiste en:
– Separar las dos cadenas del DNA (por medio de calor).
– Añadir la pequeña cadena de nucleótidos complementarios al principio del fragmento de DNA que nos interesa.
– Añadir DNA polimerasa, para copiar el fragmento que nos interesa.
11. RNA COMO MATERIAL GENÉTICO
Los retrovirus son un tipo de virus que tiene como característica que su material genético es RNA. Se trata de un RNA monocatenario. Estos virus contienen también una enzima especial, la transcriptasa inversa, cuya función es copiar este RNA viral en DNA complementario a él, con lo que se producirá un DNA bicatenario que se insertará en el DNA normal de la célula y será copiado por los mecanismos propios de ésta.
Esta enzima es muy importante, tanto desde el punto de vista terapéutico (los retrovirus son patógenos, están relacionados con algunos tipos de cánceres y uno de ellos produce el SIDA), lo que lleva a buscar fórmulas que inhiban esta enzima (con lo cual el virus no podría integrarse en la célula y no podría replicarse), como desde el punto de vista de la investigación, al permitir copiar los RNA mensajeros de distintas proteínas en DNA, que luego se puede usar como una sonda para unirse a su secuencia complementaria en la célula, lo que permite localizar el gen de una determinada proteína dentro del genoma celular. Así se pueden hacer mapas del material genético.
Las fichas bibliográficas que se incluyen son una mínima orientación, en la misma línea de datos básicos que el artículo. Al tratarse de un campo de tanta actualidad y actividad, es imprescindible recurrir a la bibliografía muy especializada para saber por dónde camina la investigación. Dado el carácter expositivo y didáctico de estas páginas no hemos dudado en utilizar también material pedagógico de Biología y Bioquímica de la Facultad de Medicina de la Universidad Autónoma de Madrid.
Ayala, Francisco J. y John A. Kiger Jr. Genética moderna, Omega. Barcelona, 1984.
Darnell, James , Harvey Lodish & David Baltimore. Molecular Cell Biology, Freeman, Scientific American Books, Nueva York, 1990.
Drlica, Karl. Understanding DNA and Gene Cloning (A Guide for the Curious), John Wiley & Sons, Nueva York, 1992.
Lehninger, Albert L. Principios de Bioquímica, Omega Barcelona 1988.
Stryer, Lubert. Biochemistry, Freeman, San Francisco 1987.
(1) X Alanina (Ala), Arginina (Arg), Asparagina (Asn), Aspartato (Asp), Cisteína (Cys), Glutamina (Gln), Glutamato (Glu), Glicina (Gly), Histidina (His), Isoleucina (Ile), Lisina (Lys), Metionina (Met), Leucina (Len), Fenilalanina (Phe), Prolina (Pro), Serina (Ser), Treonina (Thr), Triptofano (Trp), Tirosina (Tyr), Valina (Val).
Artículo extraído del nº 33 de la revista en papel Telos