La aplicación de la inteligencia artificial al estudio del lenguaje y de su representación del conocimiento humano ofrecen nuevas posibilidades de investigación y de integración de los resultados.
En los últimos años, hemos po-dido asistir a una especializa-ción en la investigación cientí-fica cada vez mayor, proceso al que no ha sido ajena la lin-güística. Esta tendencia ha sido la lógica consecuencia del vertiginoso incremento de caudal de conocimiento al que estamos asistiendo desde la revolución industrial. No obstante, este rapidísimo progreso de las ciencias ha provocado que se busquen respuestas a ciertos problemas, antes inexistentes o a los que se les daba una importancia secundaria, con carácter de urgencia.
Dos de estos inconvenientes, que se han destacado de forma relevante por afectar, aunque en distinto grado, al conjunto de las ciencias, han sido consecuencia directa de la aceleración del avance científico y de las posibilidades que ofrecen las nuevas tecnologías:
– La dificultad de manejar un elevadísimo número de datos y variables que han de ser actualizados y renovados continuamente y con gran frecuencia.
– La desvirtualización del propio objeto de estudio debido a la excesiva especialización de la investigación y a no considerar la parte que se estudia dentro de la totalidad del fenómeno que se está considerando.
Tampoco aquí el estudio de las lenguas naturales está ajeno a estas dificultades. Por ejemplo, con respecto al segundo punto, se ha dicho en varias ocasiones que en la lingüística los datos se reducen a partes muy aisladas del lenguaje por motivos metodológicos, de acuerdo con el principio de reducción del problema necesario en cualquier investigación, pero que, sin embargo, la integración de esas investigaciones locales en el conjunto teórico, necesaria para comprobar el funcionamiento global de la gramática, no se ha llevado posteriormente a cabo.
Dicha falta de integración ha dado lugar a lo que, en este caso R. Grishman (1991, 18), ha denominado la utilización de datos lingüísticos «patológicos».
Dar una respuesta no sólo teórica, sino práctica, a estos problemas ha sido uno de los objetivos de un conjunto de técnicas informáticas que bajo el nombre de Inteligencia Artificial (IA) se ha ido incorporando a la investigación científica. La atractiva idea de proporcionar un enorme número de datos a un ordenador para que éste resuelva el problema, pudiendo ser, después, actualizados sin esfuerzo, ha producido un gran número de trabajos, logrando éxitos muy importantes, pero también algunos fracasos.
Esta incorporación de la IA tanto a la Ciencias Naturales como a las Ciencias Humanas no ha sido, empero, una mera aplicación metodológica de un avance tecnológico, sino que ha influido en los propios planteamientos teóricos de las materias de estudio.
La doble influencia, teórica y metodológica, ha repercutido en las ciencias a las que se aplica la IA en varias direcciones. Podemos resumir algunas de ellas en estos cuatro puntos:
1)Influencia de estas técnicas en los planteamientos disciplinarios como nueva herramienta de verificación de hipótesis.
2)Consecuente búsqueda y aplicación de formalismos de representación adecuados tanto a la ciencia de que se trate y sus datos como a su tratamiento informático.
3)Replanteamiento y ampliación de las aplicaciones de problemas de aprendizaje y de inferencia.
4)Concepción dinámica de los sistemas que se estén investigando.
Es evidente que los cuatro puntos están íntimamente relacionados y que el tocar uno de ellos implica tratar el resto.
Por ello, las respuestas apuntadas a estos problemas han conducido a tratar de reproducir sistemas de gran complejidad de manera más global de lo que se había hecho hasta entonces,especialmente en las Ciencias Humanas.
En el caso del estudio de las lenguas naturales el tratamiento global ha sido por el momento más bien parcial. Sin embargo, la lingüística se ha visto beneficiada por la nueva herramienta informática en cuanto a la aportación de mayores posibilidades en la representación del lenguaje y en los formalismos y por el manejo de distintas materias, obteniendo así un mayor carácter interdisciplinar, tan poco común hoy día.
No quiero decir con esto que la utilización de técnicas de IA haya hecho abandonar la tendencia a la especialización (no podemos ignorar la limitaciones humanas ante el estudio del universo), pero es innegable que el uso de estas técnicas nos permite tomar en cuenta tanto factores diversos de distintas áreas de conocimiento, como el uso de diversos formalismos de gran dificultad e hipótesis pertenecientes a un sólo campo científico para solucionar un mismo problema.
La integración ha ampliado enormemente la visión que se tenía de fenómenos complejos al poder verlos en funcionamiento. Este es el motivo de que informáticos, matemáticos o químicos estén interesados por la lingüística, la psicología o la neurología y viceversa. Podríamos denominar esta situación, no sin cierta ironía, como la de un Humanismo Cibernético. Lo que no es una ironía es que la mayor globalidad y formalización en el tratamiento, sin demérito para la teoría, y la interdisciplinaridad han abierto nuevas fronteras a las ciencias y entre ellas a la lingüística.
En estas nuevas fronteras han aparecido nuevos interrogantes para la lingüística. Uno de los más importantes es el de la representación del conocimiento que se expresa a través de las lenguas naturales.
A pesar de esta introducción, hay que advertir que no voy a entrar en las páginas que siguen en disquisiciones sobre si se han cumplido o no las expectativas que la IA ha establecido desde sus orígenes, por ejemplo A. Newell & H. Simon (1958), como «dotar de intuición, introspección y aprendizaje», habilidades propias de los seres humanos, a un ordenador.
A este respecto, soy de la opinión de que mediante estas técnicas hoy día no se puede reproducir mecánicamente una lengua natural o cualquier otro comportamiento inteligente humano, de cuyos mecanismos en realidad sabemos muy poco. Como bien ha señalado E. Sabrovsky (Telos, Junio-Agosto 1992, p. 19) «nadie que conozca los problemas que plantea el lenguaje natural se atreve a decir eso».
A pesar de las limitaciones de los logros conseguidos hasta ahora por estas simulaciones para modelizar o reproducir un número suficiente de variables en el funcionamiento de una lengua natural (muchas de ellas porque de hecho no se conocen), sí se han logrado en cambio algunos resultados satisfactorios. Efectivamente, varios trabajos que van desde la programación lógica al uso de redes neuronales han conseguido reproducir ciertos comportamientos parciales, tanto regulares como irregulares.
Los retos han ido aumentando hasta la situación actual en la que son los textos reales y unidades superiores de comunicación (no sólo el sintagma o la oración) los sujetos de representación de forma dinámica, para el análisis y la síntesis (o reconocimiento y producción) en universos virtuales en donde puedan contemplarse el papel que desempeñan hipótesis, leyes y representaciones en el funcionamiento del lenguaje. La globalidad de la empresa impone que se utilice una elevada cantidad de léxico y de enunciados de una lengua dada, oral o escrita, a partir de grandes Corpus Textuales de Referencia (F.Marcos Marín -1992-).
La aplicación de estas nuevas técnicas a las teorías tradicionales y no tradicionales sobre el discurso, no cabe duda, constituye una importante aportación tanto teórica, como metodológica para la lingüística e indirectamente para otras disciplinas que tratan el conocimiento humano. En este sentido, es de especial importancia señalar la simulación de factores dinámicos dentro de sistemas cognitivos humanos,como es la memoria semántica. El dinamismo parece constituir un elemento intrínseco a ellos, tanto desde los puntos de vista diacrónico como sincrónico y de la adquisición como de la posterior evolución en la vida de una persona.
1. LA REPRESENTACIÓN DEL CONOCIMIENTO Y EL LENGUAJE
Vamos a discutir a continuación algunos problemas que plantea la representación del conocimiento lingüístico y la utilidad que las técnicas de IA tienen en la difícil tarea probatoria y evaluadora de hipótesis. Estas posibilidades que proporciona la IA suscitan, tanto en el caso de su aplicación al Procesamiento de las Lenguas Naturales, como en el resto de las Ciencias Humanas y de las Ciencias Naturales, dos cuestiones importantes: por un lado, el problema de cómo representar los hechos en sí, es decir, el conocimiento que se tiene de los objetos del mundo; por otro, el de cómo relacionar y articular las distintas representaciones de estos objetos entre sí, para adecuarlos a la realidad, primero, y permitir la aplicación de leyes y reglas, después.
Ambos problemas se agudizan de manera espectacular a medida que se aumenta la irregularidad, la individualidad y las excepciones de los objetos de conocimiento que se proporcionen a un sistema.
El problema de la representación del conocimiento se ha planteado desde muy diferentes puntos de vista.
Además de las aportaciones filosóficas de la Teoría del Conocimiento, existen innumerables incursiones por parte de la psicología, la lingüística, las matemáticas, la neurología o la informática a lo que llamamos conocimiento. Las distintas aproximaciones intentan encontrar respuestas concretas y en cierto modo prácticas para aplicarlas a sus propios estudios.
La Semiótica y la Semiología se han acercado al conocimiento lingüístico a través de distintas teorías del significado en las que se intenta desentrañar la naturaleza del signo lingüístico como unidad básica de conocimiento. Las respuestas: dadas por los teóricos han sido diversas a partir de la definición de signo lingüístico en términos de SIGNIFICANTE y SIGNIFICADO hecha por Saussure.
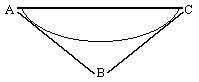
A pesar de las diferencias entre ellas, la estructura ternaria del signo lingüístico parece que no ha sido puesta en duda. Esta estructura fue propuesta en primer lugar por Ogden y Richars en 1923, y como señala J. Lyons (1977) la relación ternaria puede ser analizada en tres relaciones binarias, dos básicas y una derivada (marcada por la línea discontinua):
No hay acuerdo entre teorías que reclaman el objeto real en vez del concepto o la denotación, pero se mantiene la estructura ternaria del signo lingüístico:
1) significante o representación formal
2) significado o contenido significativo del signo
3) concepto o denotación
A partir de este esquema primario de unidad de conocimiento del lenguaje, se han desarrollado algunas formas de representación atendiendo a uno u otro punto. Por ejemplo, en sistemas de análisis sintácticos se ha apelado a las propiedades del signo más en virtud del primer aspecto y menos del segundo, dejando al margen el último. Por el contrario, los trabajos de representación del conocimiento se han centrado más en las propiedades denotativas (ya sea el objeto real o el concepto que del objeto se tiene) y de significado, sin prestar mucha atención a las peculiaridades y propiedades del signo lingüístico en cuanto a su forma.
Las dificultades de la necesaria distinción entre lenguaje y pensamiento y de conjugar las propiedades de los distintos aspectos del signo lingüístico no han sido satisfactoriamente superadas.
Pero si la representación del conocimiento del léxico plantea todavía serios interrogantes, la representación de unidades de conocimiento superiores, que podemos denominar de comunicación, como la oración o el enunciado, entraña problemas e interrogantes de mayor complejidad.
Si partimos de los niveles de estudio tradicionales de la lingüística: fonética, fonología, morfología, sintaxis, semántica y pragmática, caemos en la cuenta de que a medida que ascendemos en el nivel de estudio la dificultad de representación aumenta, sobre todo si no renunciamos a integrar unas representaciones en otras.
Esta integración es necesaria pues si bien el conocimiento que una lengua expresa está almacenado en un léxico, es un conocimiento proposicional, es decir, está compuesto a partir del léxico y la gramática en unidades de comunicación como el enunciado. Estamos, pues,ante una tarea nada trivial.
Así, si partimos del propio conocimiento, del concepto, encontramos nuevas etapas en el proceso de las tareas de representación:
Este enfoque, denominado onomasiológico, pretende llegar al contenido mismo del lenguaje de tal manera que todo, incluyendo la morfosintaxis, quede supeditado a lo que se denomina genéricamente como «significado», para así acceder al conocimiento del mundo que se logra a través de los sentidos y de la interacción comunicativa. Podemos ver, pues, dos dicotomías: conocimiento y formalización lingüística (lengua natural) por un lado y representación del conocimiento (base de conocimiento) y formalización de la representación por otro. Si conformamos ambas dicotomías en forma de quebrados en un acto de abstracción metafórica y establecemos la relación entre ambas, obtenemos una fórmula en forma de una regla de tres, si no de igualdad, sí de equivalencia:
Conocimiento/legua natural = Base de conocimientos/Forma de representación
Si consideramos que la incógnita (1) (X) es el conocimiento, obtenemos la siguiente ecuación:
X = (Lengua natural X Base de conocimiento)/Forma de la representación
De acuerdo con ella, el conocimiento es directamente proporcional al Lenguaje Natural y a la Base de Conocimiento, mientras que lo es indirectamente al formalismo de la representación. Podemos fácilmente interpretar este hecho de la siguiente manera:
En una investigación, cuanto más se conozca el lenguaje natural y más amplia y detallada sea la Base del Conocimiento más cerca estaremos de alcanzar la naturaleza del conocimiento humano. Pero si complicamos excesivamente el formalismo de la representación que utilicemos, es decir, aumentamos su carácter ad hoc, corremos el peligro de desaprovechar los datos proporcionados por los otros dos factores, en detrimento de la propia materia de estudio objeto de la investigación.
De este símil matemático, casi un juego, podemos extraer dos interesantes conclusiones:
1)Tanto el estudio del lenguaje natural como la creación de una base de conocimiento han de ser lo más amplia posible para evitar así que la parcialidad de los datos nos aleje de la realidad.
2)El formalismo que utilicemos debe facilitarnos la labor de investigación y representación y acercarse, por tanto, lo más posible al objeto representado,huyendo de complejas metalenguas que aportan más confusión que claridad.
Podemos, en este punto, hacer una distinción metodológica entre el conocimiento numérico y el conocimiento simbólico, con riesgo de excluir algún tipo de conocimiento que no pueda ser encuadrado en uno solo de estos dos grupos.
Efectivamente, en el ámbito de las representaciones numéricas o conexionistas las dificultades anteriormente mencionadas se evitan desde el momento en que se pueden realizar las operaciones matemáticas que se deseen a gran velocidad y la formalización utilizada nace del seno del propio objeto de estudio.
Así lo han demostrado, aunque sin duda queda mucho por hacer, las aplicaciones de las redes neuronales (simulaciones del sistema de la visión, reconocimiento de imágenes y caracteres, etc.) a problemas matemáticos o biológicos.
No ha ocurrido lo mismo con las representaciones simbólicas, como puede ser la de una lengua natural. Sin embargo, los avances en arquitecturas paralelas reales (máquinas con varias memorias-procesadores) o simuladas (Programación Orientada a Objetos) han superado la concepción del programa como datos y procedimientos separados (memoria y procesador).
Aquí el componente operativo no es un programa que actúa sobre unos datos, sino que los datos dirigen el tipo de proceso que cada unidad ha de ejecutar mediante marcadores. También un acontecimiento puede dirigir el proceso a realizar por los objetos afectados al ser activada una parte implicada en una situación en curso. Estos enfoques suelen están recogidos en Sistemas Dirigidos por Datos y Eventos, los cuales se apartan, como hemos visto, de la programación tradicional. De ellas, las más conocidas hasta ahora en la representación simbólica han sido las Redes Neuronales y la POO y los conceptos y principios formales de representación que se han derivado de ella. La nueva estrategia de programación ha permitido conjugar la representación simbólica y conexionista en la IA. Algunas de estas técnicas ya han tenido primeros resultados en el procesamiento del lenguaje natural (PLN a partir de ahora).
Una crucial repercusión que ha tenido este hecho ha sido el replanteamiento de la naturaleza y potencial relacional de las unidades mínimas de representación, a partir de ahora objetos. En este sentido podemos diferenciar tres tipos de objetos (además del objeto real que no consideramos dentro del conocimiento, sino como cognoscible): objeto conceptual, objeto lingüístico y objeto informático. El salto desde el objeto real hasta el objeto informático, pasando por el lingüístico es todavía un reto no superado, pero cualquier avance en uno de los tres, supondrá un avance en los otros dos.
2. SISTEMAS DE REPRESENTACIÓN
Vamos a proseguir el acercamiento al problema de la representación o transferencia de conocimientos a un ordenador, dentro del ámbito de estudio de las lenguas naturales, hablando de algunos de los sistemas de representación antes mencionados. Ya que no es posible hacer un amplio repaso, presentaré a grandes rasgos algunas estrategias planteadas hoy día para centrarme finalmente, con mayor profundidad, en introducir una de ellas.
Uno de los sistemas ya tradicionales de la Inteligencia Artificial son los denominados sistemas expertos. El concepto de sistema experto es muy amplio y no podemos detenernos aquí a intentar exponer sus características (2). Sí podemos decir, sin embargo, que el sistema experto tradicional está pensado como auxiliar de un usuario, es decir, el usuario proporciona al sistema los datos a tener en cuenta y el sistema experto proporciona una o varias soluciones.
Otro método, tradicional del PLN que usan la IA es el uso de las listas con cierto nivel de estructuración sobre las que actúa un analizador o sintetizador y un motor de inferencia (como por ejemplo el clásico algoritmo de backtracking utilizado en PROLOG). En los años setenta y ochenta se han desarrollado motores de inferencia capaces de tratar representaciones con un cierto grado de satisfacción, como es el llamado algoritmo rete. Pero todos ellos basan sus resultados en el reconocimiento del patrón (pattern matching) y en la unificación de rasgos, lo cual no permite, si no se les proporciona además otro tipo de mecanismos y heurísticas, el tratamiento de las excepciones.
Para obtener buenas representaciones se ha procedido a la minimización de los estados de representación. No obstante, la experiencia ha demostrado que no es posible esta minimización sin tener en cuenta tanto fenómenos de ámbito global como de ámbito local y cómo éstos afectan al sistema globalmente.
Hay que decir, no obstante, que estos mismos lenguajes de programación (como LISP, por ejemplo) permiten en la actualidad desarrollar estrategias y sistemas más complejos, los cuales sí usan automáticamente los datos que le son presentados y las acciones que se activan entre ellos, actuando en consecuencia. Son los llamados sistemas dirigidos por datos y eventos (Data & Event Driven System), que hemos mencionado anteriormente.
Sistemas dirigidos por datos y eventos
El caso estándar de este tipo de sistemas es la programación dirigida por datos (Data Driven Programming). Este tipo de programa puede ser visto como una especie de caja negra con datos de entrada y salida. Aun así, los datos no ponen el programa en acción. Por ello, se necesita un evento, el cual es normalmente un usuario que invoca el programa y le suministra datos.
Los sistemas de programación dirigidos por eventos (Event Driven Programming) aplicados a las lenguas naturales, como son algunos lenguajes de programación como Basic, PL1, SmallTalk, ADA responden a otro tipo de procedimiento. Este consiste en que los programas esperan que un estado particular del entorno que describen ocurra, cuando llega ese estado se ponen automáticamente en acción. Un ejemplo de estos sistemas son los movimientos del ratón electrónico o los teclados, sistemas manejados con programación dirigida por eventos.
Es, pues, otra manera de ver el mundo exterior, si lo podemos expresar así, en la cual tenemos una estrategia peculiar de tratar con los datos de entrada. Su peculiaridad consiste a grandes rasgos en un sistema orientado hacia un funcionamiento a través de mensajes, como lo es típicamente cualquier universo de objetos, el cual actúa y se reorganiza dirigido por un evento, o las redes neuronales (activando las neuronas que logran alcanzar el umbral de acción). Otro sencillo ejemplo de este tipo de programación es la manera que tienen los ordenadores Macintosh de reconocer la disquetera (floppy) en la que el usuario inserta el disco (floppy disk), actuando en consecuencia, a diferencia de los PC compatibles, los cuales no reconocen si se ha insertado en la unidad A o B.
Esta programación supone, por un lado, hacer descripciones atomizadas en objetos independientes que constituyen un programa por sí mismos y pueden, al mismo tiempo, entrar en relación e interactuación con otros objetos de su mismo entorno, y por otro, integrar los datos y los procedimientos de tal manera que pueda cambiar el proceso por el advenimiento de nuevos datos o de un estado de hechos, conjunto estructurado de datos relacionados, particular.
Por último, existen también estrategias y lenguajes de programación pensados para diseñar entornos de objetos simbólicos y mecanismos conexionistas dirigidos tanto por datos como por eventos. Más tarde expondremos un ejemplo de ellos denominado Dynamic Binding (DynaB) (3).
Redes neuronales
Las redes neuronales (4) son modelos matemáticos para describir propiedades de colectivos de unidades similares que interaccionan entre sí, y están inspirados en modelos físicos y neurobiológicos (sólo inspirados ya que los modelos originales no se conocen lo suficiente). Estos modelos son utilizados en ordenadores convencionales. Son ya varios los modelos de redes neuronales que se han construido, sobre todo en la simulación de la visión. Existen también algunos ejemplos de aplicaciones al lenguaje, como la red de aprendizaje de verbos en inglés de Grossberg.
Son, básicamente, colectivos de representaciones de neuronas o átomos en términos de rasgos y valores numéricos, los cuales responden a un estímulo también numérico y orientado a uno o más rasgos cuando éste alcanza un umbral de potencial de acción suficientemente alto. Los umbrales de potencial de acción pueden ser distintos para cada neurona o nodo y sus efectos pueden ser tanto de estimular a otras neuronas como de inhibirlas. Una serie de factores, como los pesos que tienen cada una de las conexiones, intervienen en la cantidad de estímulo que le llega a la neurona. Estos colectivos de neuronas suelen además estar dispuestos en distintas capas, unas visibles y otras no.
Las propiedades que hacen útiles estas redes son la existencia de algoritmos de aprendizaje a partir de ejemplos, por un lado, y la estabilidad frente a los errores en algún componente, por otro. Son, pues, sistemas que van aprendiendo poco a poco, estabilizándose la red hasta obtener la configuración y resultados deseados.
Dicho proceso de aprendizaje puede ser descrito con este ejemplo:
1)Se presentan los ejemplos a la red (secuencial o aleatoriamente).
2)Se modifican los pesos según la diferencia entre los valores de salida obtenidos y los valores deseados.
3)Se repite el proceso una y otra vez hasta alcanzar un mínimo en la función de error propia de
sa red.
El aprendizaje inicial puede ser lento dependiendo de las dimensiones del caso y del ordenador que se utilice, pero las respuestas de las redes entrenadas son siempre muy rápidas y la actualización con ejemplos nuevos es rápida si modifican poco el saber de la red neuronal.
Como puede observarse, estas redes tienen un funcionamiento realmente interesante, para muchos y complejos problemas. El problema para nosotros,en cambio, es su forma de representación. No podemos representar hasta el momento el lenguaje con su complejidad sintáctica y mucho menos su semántica, en un nivel tan minúsculo como es el neuronal. Para ello, necesitaríamos una simplificación y fragmentación de los datos y las operaciones que no está disponible. En la división y simplificación de las representaciones y su programación tenemos que detenernos mucho más arriba, quizás, en el nivel de las unidades léxicas.
Además, las redes neuronales, muy útiles para complejos sistemas numéricos, tienen dificultades en su aplicación a complejos sistemas simbólicos, como los que estamos tratando aquí, aunque se utilizan sus principios en otras estrategias como la POO. Se ha necesitado, pues, un procedimiento de programación que tenga las cualidades de las redes neuronales pero que simplifiquen su representación y faciliten el tratamiento simbólico.
Programación orientada a objetos
A diferencia también de la programación tradicional, en la que un programa es concebido como una colección de procedimientos a los que le son pasados una serie de parámetros, los cuales son manipulados para devolver, por ejemplo un valor, en un sistema orientado a objetos el universo se ve como una colección de objetos. Cada uno de los objetos pequeños programas independientes pero interrelacionados, de tal manera que tiene su propio nombre, sus propias propiedades, valores y variables y sus propios procedimientos.
Los objetos, aunque diferentes de neuronas o átomos, como en las redes neuronales, también se comunican entre sí para que se activen unos objetos a otros y se estabilicen todas las relaciones entre sí comunicándose entre sí mediante procedimientos. Los objetos son, pues, entidades activas: un objeto investiga las peticiones que le llegan y actúa en consecuencia; pero no numéricos: las propiedades y procedimientos pueden ser numéricos (una operación) o simbólicos (asignar un nuevo valor a un rasgo).
Estos objetos, basados en los marcos (frames, Minsky, 1975), proporcionan un medio de combinar declaraciones y procedimientos dentro del mismo entorno de representación. Según Minsky (5) los contenidos procedurales y declarativos de problemas como el razonamiento y el lenguaje deberían estar conectados y estructurados para poder explicar la potencia y velocidad de las actividades mentales.
En este sentido, la comprensión del lenguaje es una de las dos vertientes desde la que podemos acceder al conocimiento que expresa una lengua natural, la otra la producción del lenguaje. Dentro de la dificultad que ambas perspectivas poseen, la recepción pone al alcance más datos para tratar de reconstruir la semántica del lenguaje, sobre todo si se utilizan datos o textos reales.
Es un buen punto de partida para estudiar el conocimiento y los mecanismos del lenguaje.
El funcionamiento de estos marcos en labores de reconocimiento se puede describir en pocas palabras de la siguiente manera: ante una nueva situación, una palabra de un nuevo texto, por ejemplo, se selecciona en la memoria una estructura fundamental denominada marco.
Este es un modelo o varios modelos que se recuerdan para ser adaptados a la realidad mediante cambios de detalles cuando sea necesario. Dicho de otra manera, podemos hacer corresponder marcos que contengan conjuntamente la representación de las propiedades estáticas de los términos (semántico-conceptual y semántico-léxica) junto con sus propiedades dinámicas (semántico-sintáctica) en un marco el cual nos sirve de referencia para reconocer esos mismos términos en nuevos textos, ofreciendo la posibilidad de modificar detalles que no afecten fundamentalmente a la estructura, o que no permitan confundir dos marcos muy relacionados.
Son, pues, básicamente útiles para representaciones simbólicas.
Estos objetos sólo son visibles en parte, es decir, cada objeto tiene una interfaz pública y una representación e implementación privada. Las características generales de esas representaciones son:
a)la creación de un entorno de objetos (un objeto puede estar jerárquicamente relacionado con otro como su metaclase, clase, subclase, etc., como high frequency es una subclase de frequency) los cuales contienen una descripción estática (aquellas propiedades observables que en sí mismas no suponen un comportamiento) y una dinámica (los comportamientos de ese objeto);
b)la herencia múltiple, gracias a la cual un objeto puede heredar atributos (tanto propiedades como comportamientos) de otros objetos en los que está encapsulado o con el que tiene una relación genética de este tipo. Se llama múltiple porque puede heredar propiedades procedentes de varios objetos pertenecientes a varias clases;
c)envío de mensajes entre los objetos.
Los objetos, en virtud de estas características, se dividen en clases e instancias. La clase contiene las definiciones de los objetos, así como los procedimientos adecuados a esa clase de objetos. Los objetos instancia tienen sus propios valores de atributos, y todos comparten los operadores.
En la parte procedural, que contiene las reglas, los objetos se envían mensajes entre sí activando métodos de funcionamiento formados por un selector y unos argumentos. El selector elige, entre todos los métodos asociados a un objeto, el apropiado. También existen otro tipo de procesos llamados demonios que se activan autónomamente si un determinado estado de hechos aparece, y pueden afectar a la globalidad.
Esta información está estructurada dentro de los propios objetos, dividiéndose entre lo que se llama descripción estática, propiedades inherentes del tipo material, color, componentes, etc. y descripción dinámica como comportamientos, usos, acciones, procedimientos, etc.
Así, pues, los lenguajes orientados a objetos pueden ser dirigidos por datos, dirigidos por eventos o dirigidos por datos y eventos, hecho muy importante para nosotros a la hora de tratar enunciados u oraciones, ya que predican eventos, no sólo datos.
Pero ¿qué podemos obtener gracias a esta manera de representar y programar? En lo que a nosotros respecta, hallar representaciones semánticas adecuadas que combinen los diferentes tipos de información señalados anteriormente, producen análisis en forma de red.
Si obtenemos estas redes de representación, hallaremos el soporte en donde aplicar las reglas de preferencia de interpretación semántica, según se aleje o se aproxime más a los modelos de marcos típicos.
Para ello habrá que encontrar un analizador que esté dirigido por las propias palabras, cada término ha de analizar su propio entorno, que intervienen en un enunciado. De esta manera, estaremos en el camino de un análisis y una representación conceptual, semántica y sintáctica adecuados para reconocer, al menos, los contextos más típicos de un término.
Para la ejemplificación podemos utilizar el sistema y entorno de programación de objetos DynaB (6) en el que existen una serie de primitivos a partir de los cuales el universo de cada aplicación ha de ser creado. DynaB permite, al funcionar en modo de diálogo y como intérprete, ir mejorando y refinando la implementación con rapidez. Vamos a mostrar aquí algunos ejemplos muy simplificados de la formalización e implementación de los objetos, aunque no de los métodos, en código LISP en DYNAB, que dependen de la aplicación concreta.
Es importante, como hemos señalado más arriba, utilizar textos reales (un corpus representativo) para su análisis, formalización e implementación, tanto para observar las propiedades y comportamientos del léxico y términos, como para estudiar el valor de las marcas gramaticales. En este sentido, queda mucho por hacer.
Los objetos
Podemos distinguir los dos siguientes niveles en un universo de objetos:
1)Descripción y diseño macroscópicos de red: objetos, herencia múltiple, jerarquía, métodos (múltiples dentritas, único axón).
2)Descripción y diseño microscópico de red: objetos propiedades estáticas y dinámicas
En la siguiente figura podemos ver una simple representación del nivel macroscópico de red en el que cada letra representa un objeto (7).
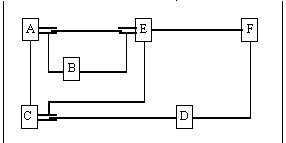
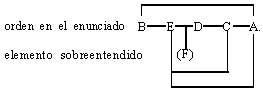
El hablar o el escribir un texto nos obliga a yuxtaponer las relaciones de una manera lineal ya que el lenguaje natural se desarrolla en una secuencia temporal. Esta linearización impone necesariamente un orden de palabras que refleja el punto de vista del enunciante. El resultado del análisis del enunciado será entonces una red como la que se muestra a continuación, teniendo en cuenta el punto de vista del enunciante.
Una simple representación de un objeto léxico el cual corresponde con una o más situaciones típicas evocadas, será para, por ejemplo, el verbo transmitir la siguiente:

Mientras que la representación de una situación singular en la que interviene transmitir como «Los países asociados trasmiten los datos desde la estación terrena al satélite» será (8):

El elemento sobreentendido del cuadro sobre el orden del enunciado tiene básicamente que ver con procesos de auto-organización, mientras que el c) lo tiene con el concepto de cableado (cablage), propuesto por G.Bernard (1990), establecido entre los elementos de las redes de conocimientos y que podemos ejemplificar con el siguiente esquema:
Cableado en red de conocimientos (9)
Vamos a continuación a hablar del entorno de objetos, la red de objetos y la red resultante. Hemos separado esta presentación en tres aspectos por razones metodológicas, pero recordamos aquí que el entorno en el que se encuentran es el mismo, es decir, todos los objetos pueden llegar a comunicarse entre sí. La representación de cada singularidad, de acuerdo con lo hasta ahora expuesto la podemos resumir con el siguiente esquema (10):
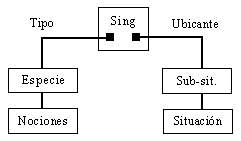
Este esquema se simboliza en el siguiente marco:

Este esquema de representación aplicado a un simple ejemplo como el satélite da como resultado el siguiente:
«el satélite»
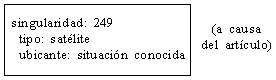
Este esquema corresponde a la palabra satélite a priori sin pertenecer a la terminología de telecomunicaciones, pues no tenemos datos suficientes, está fuera de contexto. En cambio, en el siguiente ejemplo, aunque también fuera de contexto, tenemos ya suficiente información para adscribir esta expresión en la terminología que estamos tratando:
«el satélite de comunicaciones»

Esta singularidad hará las llamadas pertinentes a sus tipos respectivos, los cuales determinarán la ubicación de dichos tipos:
Pero lo que se realiza en el enunciado específico «el satélite de comunicaciones» son las relaciones de ubicación singulares siguientes:

Es interesante observar que en este tipo de expresiones encontramos una ubicación que aunque no llega a ser recíproca, sí podemos decir que es correspondida con diferente intensidad, dependiendo, por ejemplo, si les une una preposición o no.
De nuevo aquí notamos la falta de trabajos en torno a los valores semánticos de las marcas gramaticales. En este caso, este tipo de estudios serían esclarecedores de las relaciones que se establecen entre los elementos de un multitérmino o término compuesto.
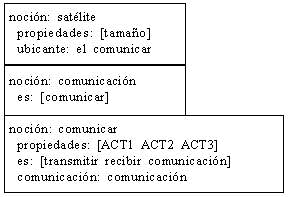
El valor de dichas marcas unido al propio valor de los elementos léxicos plenos que lo componen podrían permitirnos perfilar mucho mejor este tipo de representaciones. Representación de la red simbolizada que se concreta en otro tipo de formalización acorde con los marcos descritos como vemos a continuación:
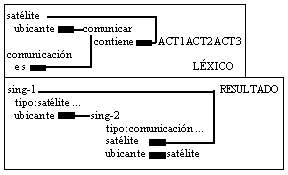
De éstos, el primero corresponde a la descripción léxica del diccionario, las relaciones que establecen los elementos, mientras que el segundo es el resultado de la red de relaciones que se establece en el enunciado, es decir, del método existente para crear este marco.
Así se puede representar en el objeto, en vez de las redes resultantes o estructuras formadas directamente, los métodos para construirlas.
El aspecto estático de la modelización está compuesto de atributos de sistema, clase e instancia:
* objeto: señal
proto: clase
supers: [nombre femenino telecomunicaciones]
globs: [analógica digital]
analógica: sí/no
digital: no/sí (11)
Si representamos una subclase de señal, especificaremos nuevos atributos:
* clase: analógica
supers: [adjetivo femenino señal]
globs: [frecuencia]
frecuencia: sí
props: [MDT]; Multiplexión por división de tiempo
MDT: sí
Y así sucesivamente, ampliando y estableciendo otras relaciones colaterales. Como vemos los valores de los atributos pueden ser objetos, conjuntos o listas, un valor neutro o no especificado o algún tipo de descripción:
* clase: frecuencia
supers: [nombre femenino señal]
globs: [modulación]
modulación: sí
props: [medida]
medida: [], tipo (numérico Hz.)
* clase: modulación
supers: [nombre femenino proceso analógica]
globs: [frecuencia]
frecuencia: [], tipo: (AM FM PM)
props: [arg1 agente]
arg1: [], tipo: (frecuencia, señal)
causa: [], tipo: (modulador)
Demonios
Estos atributos poseen, como vemos, ciertos descriptores de atributos. DynaB dispone seis descriptores de atributos a la descripción estática (12) y además de otros cinco que en realidad son desencadenadores de demons.
Un demonio es un fragmento de código ejecutable unido a un atributo; se presentan como expresiones simbólicas evaluables y están constituidas de funciones con sus argumentos, es decir, pertenecen a la descripción dinámica. Los demonios primitivos que en DynaB podemos encontrar son init, To Fill (TF), When Filled (WF), When Needed (WN) y When Removed (WR).

Por poner un ejemplo de su función, podemos citar la reacción TF o reacción en lectura, que determina el valor de un atributo y contiene una lista de expresiones entre [] que serán evaluadas de izquierda a derecha para obtener un valor correcto (13).
Por el contrario una reacción WF o reacción en escritura, describe, bajo la forma de una serie de demonios, la reacción de un objeto a la modificación, esto es, escritura, que tenga lugar en un momento dado. Ofrece la posibilidad de describir localmente, en el nivel del atributo, las consecuencias de la aserción de un valor lo que permite una programación que no sólo dirija el comportamiento general por los datos, sino por los fines de los datos, por los valores que adquieren en un momento dado (14).
Cada atributo está, por lo tanto, restringido por su modo y sus descriptores de atributo. Por ejemplo, entre los utilizados más arriba, proto y supers deben hacer referencia a clases ya existentes en el entorno descrito, mientras que globs y props son auto-definitorias o el hecho de que puedan tener uno sólo o varios y de que éstos sean evaluables o no.
Los demonios por su parte se evalúan en serie y la evaluación de un demonio puede llevar a la evaluación de otro, operando con resultados de operaciones anteriores. También es posible inhibir temporalmente el mecanismo de evaluación y ser reactivado cuando se desee. Existen además una serie de los mecanismos interactivos entre el sistema y el usuario para la creación de los objetos.
Los mensajes y los métodos
Como vimos, los objetos se envían mensajes entre sí, los cuales son seleccionados por algunos de ellos, pudiendo provocar distintas reacciones: envío de otro mensaje, que el objeto se comporte de determinada manera o que se manipulen valores de los atributos, etc. El sistema prevé una serie de mensajes y métodos asociados primitivos (15). Pero pueden ser creados tantos mensajes y métodos como sean necesarios.
Por ejemplo, dijimos que desde una visión operacionalista o funcionalista del lenguaje las preposiciones son contempladas como marcas formales o índices de operaciones. Delimitar el valor semántico de una preposición es en consecuencia hallar la operación que lleva a cabo por las unidades afectadas por esa preposición. La gran dificultad de hallar este valor viene dada por la confusión que se produce entre las propiedades del contexto y las de la marca, en este caso la preposición. Hay pues que distinguir lo que aporta semánticamente la preposición de lo que aporta el contexto.
Normalmente nunca se le ha dado un único valor a una preposición por este motivo.
Sin embargo, un formalismo dinámico permite, como hemos visto, encadenar e inhibir operaciones de tal manera que desde un único valor inicial, una función primitiva f se obtengan variedad interpretaciones al encadenarse con operaciones distintas, como mostramos en el gráfico:
* situación: «me puse el collar de zafiros»
contenido: [poner-l collar-l]
* clase: poner-l
props: [poniente puesto destinatario]
poniente: yo ;por la terminación
puesto: collar-l ;por el orden
destinatario: yo ; por el pronombre
* clase: collar-l
supers: [portátil ;compatible con poner
props: [localización materia]
localización: conocida ;por el determinante
materia: zafiro-l ; por el orden
* clase: zafiro-l
supers: [materia] ;compatibilidad con collar:materia
props: [número origen]
número: plural ;por la terminación
origen: collar-l ;por la preposición (16)
Evidentemente es necesario establecer una configuración con los mecanismos de jerarquización y de comunicación estática entre objetos que poseemos. Además, la descripción de objetos primitivos (ontología) ya instalados que sirven de base o de conocimiento extralingüístico hay que anticipárselos y dárselos como conocidos; por ejemplo, los imprescindibles para la comprensión del enunciado anterior podrían ser:
base: texto * clase: portátil * clase: cuidar
cpack: ctext * clase: portátil supers: [acción]
acción: [edmode] * clase: cosa Aktionsart: durativa
* clase: acción props: [recibe localización] props: [cuidante cuidado]
props: [Aktionsart] * clase: humano * clase: situación
* clase: materia supers: [cosa] props: [contenido]
* clase: graduable props: [hace pertenece tiene] * clase: yo
* clase: color * clase: medio supers:[humano [humano]
* clase: cuidable hace : [extremar-l bañar-l poner-l]
tiene: indumento-l
Los mecanismos de inferencia
Aspecto dinámico del sistema DynaB: definición y utilización de reglas (meta-demonios). Se describen la sintaxis y la semántica de las reglas a través de numerosos ejemplos que introducen los conceptos necesarios para la construcción de sistemas expertos. Están comprendidas también algunas técnicas de exploración del universo de conocimientos de un sistema experto: propagación e inferencia:
a)el motor de inferencia hacia delante enriquece progresivamente una base de hechos inicialmente constituida de objetos y de afirmaciones que la han creado al principio buscando una regla en la que todas las premisas pertenecen a la base de hechos y le añade a ésta el nuevo hecho proporcionado por la conclusión de la regla ya que sabe deducirlo de hechos ya conocidos. El motor se para cuando la conclusión buscada aparece en la base o mediante una regla;
b)el motor de inferencia hacia atrás busca una regla teniendo la finalidad de partida como conclusión, dándose las premisas de las reglas como nuevos fines, salvo si son datos del problema. El motor busca entonces una nueva regla que conduzca a uno de estos fines, y continúa así hasta que todos los fines intermediarios sean alcanzados, o hasta que no se encuentre una regla aplicable.
La elección de uno u otro depende del objeto del sistema experto. El sistema realiza un diagnóstico al que se le pregunta cuál es la consecuencia de los fenómenos que observa, utilizando el motor de inferencia hacia delante si el objetivo se desconoce en el punto de partida, o hacia atrás cuando el sistema debe responder a una cuestión precisa, como puede ser determinar la aplicación de cierta operación.
El propio sistema está constituido de objetos y métodos. La descripción técnica del entorno permite al programador redefinir los objetos y los métodos primitivos con el fin de adaptar el lenguaje a una aplicación particular.
El programador está en constante interacción con el sistema.
Existen ciertos diálogos que son sometidos a un protocolo para simplificar la detección y la supresión de errores que comprometerían la coherencia de la descripción.
Las distintas capas de la implementación (1) se van sucediendo dentro del mismo entorno de objetos, de abajo hacia arriba, MuLisp, DynaB, comprehensor (motor de inferencia), aplicación a una lengua natural, que es la capa que contiene en realidad los objetos lingüísticos que nos han interesado aquí.
El problema del aprendizaje
Tratamos brevemente el tema del aprendizaje cuando hablamos de redes neuronales.
Dijimos que estas redes han de ser entrenadas mediante exposiciones sucesivas a ejemplos. En el caso de los lenguajes orientados a objetos, el entorno de objetos se va creando y enriqueciendo con la presentación de nuevos eventos. Esto produce la eventual incorporación de nuevos objetos y sus marcos correspondientes, como nuevos marcos para objetos ya conocidos. Así, el entorno resulta enriquecido, refinado o ampliado, a cada nueva presentación de un texto.
Por supuesto, el programador tendrá que ir enseñando y creando ese universo, pero el programa podrá tratar con los enunciados desde el momento en que conozca los objetos que intervienen, debiendo calcular su relación semántica. Es pues el cálculo de la relación semántica lo más importante de este proceso. Cuanto más aprenda el programa aprovechará más cálculos semánticos ya hechos para aplicarlos a nuevos eventos que se correspondan a ese mismo cálculo.
No es necesario decir aquí lo potentes que pueden ser las técnicas de aprendizaje en el PLN. No obstante, el problema del aprendizaje es de una gran complejidad y requeriría un estudio más profundo.
Simplemente, a modo de ejemplo, podemos dar aquí algunas estrategias de aprendizaje que pueden ser utilizadas.
Uno de los procesos de aprendizaje que sería conveniente tener en cuenta está basado en el concepto de autoorganización (17). La autoorganización es una característica del sistema. Un sistema autoorganizativo es aquél que distingue entre la unidad del sistema en sí como representación y su fondo o contenidos concretos en un momento dado. Se interesa por aquellas en las que es posible hablar de los eventos propios y los eventos que pertenecen al medio, o dicho de otra manera, entre los distintos estados de un universo que va evolucionando y el transfondo de bases y principios organizativos de ese universo. Ambos ámbitos tienen una superficie de acoplamiento en donde se crean influencias mutuas, aunque sólo en algunas de sus dimensiones. Como ejemplo, la teoría de sistemas nos provee de un paradigma de acoplamiento puntual que se basa en el siguiente principio: un dato o evento entrante (input) transforma la dinámica de los estados de un sistema. Esto lo podemos expresar con la siguiente fórmula:


En donde vemos que esta autoorganización es controlada pues sólo unos cuantos inputs son permitidos. Esto va a favor del principio de máxima recuperabilidad que indica la necesidad fundamental de conservar la información original. En nuestro caso, esa información metasistémica la podría constituir el entramado de relaciones conceptuales y ciertas características semántico-sintácticas muy poco invariables. Así, las relaciones entre los objetos pueden verse modificadas, por ejemplo ordenadas, o refinadas, por nuevos eventos que pueden aportar información precisa a través de la nueva instancia.
Así, los espacios de input permitidos, como pueden ser restricciones en el número o tipo de modificadores con los que puede coaparecer en un texto, limitan y controlan la organización de los nuevos datos.
Otro mecanismo de aprendizaje es el llamado cableado de relaciones (18), el cual consiste en reforzar los caminos más usados o las relaciones más frecuentes entre los objetos (reforzamiento por la experiencia de uso). De tal manera que ante, por ejemplo, la aparición del objeto estación y del objeto terrestre, por lo usual en anteriores experiencias textuales, la relación se establezca casi instantáneamente; sea lo primero que tanto el uno como el otro vaya a buscar. El resultado es, por una parte, una autoorganización de las conexiones (dirigida por eventos), y por otra, un ahorro de búsquedas, de operaciones y por tanto de tiempo de procesamiento y de memoria.
Este tipo de trenzado o cableado puede afectar, por supuesto, también a los métodos y procedimientos, estableciendo por ejemplo secuencias más óptimas que otras.
El proceso de abstracción de los datos es sin duda un requisito fundamental del estudio y la investigación científica. Este proceso, no obstante, ha constituido un problema desde el mismo momento de su formalización: ¿cómo abstraer los datos sin modificarlos de alguna manera?
Este problema es en cierta forma especialmente agudo en la lingüística pues normalmente se le ha unido a la abstracción una sincronización, es decir, el tomar los datos de una sección temporal determinada, eliminando así el componente fundamental de dinamismo que tienen las lenguas naturales.
Son pues necesarios modelos de representación dinámicos, que permitan globalizar la representación sin perder matizaciones en los fenómenos locales. Así, por ejemplo, la activación de un método global, que afecte a todos los objetos, como la formación de femeninos, puede activar un demonio en un objeto determinado (reaccionando con un selector determinado al mensaje producido por el método general y expandido en la red), de tal manera que se anule el efecto de la regla global y se provoque otro efecto local. Un ejemplo simple entre los muchos posibles puede ser el hecho de que la forma femenina de caballo no sea caballa, según la regla global, sino yegua, según la regla local.
Hemos visto también que el objeto de estudio, la metodología y las herramientas que se utilicen se influyen de alguna manera mutuamente. Así, el doble aspecto de las representaciones de objetos, estáticamente y dinámicamente, nos abre expectativas de experimentación muy interesantes.
Por un lado, el de almacenar la información semántica que organiza la memoria clasificando las palabras y sus funciones y realizaciones potenciales de manera que pueda ser utilizada en procesos de composición y descomposición de enunciados. Por otro reglas y operaciones cuyo ámbito de actuación es fácilmente controlable.
Este sistema de representación, lejos de dar todas las respuestas, permite además ir integrando la información que ha que representar de los distintos niveles de estudio lingüístico, fonética, fonología, morfología, sintaxis, semántica y pragmática. La programación de esa información está simplificada ya que se va introduciendo objeto a objeto.
Para mostrar una posible nueva vía de investigación, supongamos que seleccionamos los tres o cuatro libros básicos de la cultura de una lengua y vamos analizando y programando en un entorno de objetos los enunciados que van apareciendo, de manera que:
1) Una instancia pueda crear un nuevo tipo no existente
2) Las propiedades de las instancias recojan las del tipo, las propiedades de las clases a las que pertenezca, etc (herencia múltiple)
3)Las propiedades de tipo se enriquezcan con las propiedades comunes de todas las instancias.
4)Las acciones del sistema y de reacciones de los objetos imiten el valor operativo de los elementos formales del lenguaje (orden, entonación, palabras gramaticales).
5)Existan mecanismos de aprendizaje para que:
a)las relaciones estáticas se configuren (reforzándose, debilitándose y atajándose (cableándose) las uniones) y se modifiquen mediante nueva información
b)las relaciones dinámicas se estabilicen (la programación de una gran cantidad de texto permita que se vaya matizando, refinando y detallando el entorno mediante mecanismos de autoorganización)
Muchas cosas se nos escapan en este planteamiento, pero las dichas hasta ahora bastan para mostrar la idea.
El hecho de que el sistema lingüístico que se defina preconfigure la estructura de la lengua pero dejando a la experiencia de nuevos textos (para aprender vocabulario y gramática como lo haría un niño) la consolidación y paulatina mejora del conocimiento de una lengua nos puede llevar a percatarnos de algunos aspectos sobre el funcionamiento del lenguaje que no habíamos observado a partir de la observación de la evolución del prototipo de imitación de comprensión del lenguaje que hemos reproducido en el ordenador.
Los logros de este tipo de experimentos más que constituir puntos de llegada en la comprensión del lenguaje natural podrían constituir nuevos puntos de partida. No es sólo la reproducción artificial de un comportamiento inteligente lo que persigue aquí, sino más bien el aproximarnos a comprender la inteligencia natural, a través del lenguaje natural, mediante la observación de reconstrucciones más o menos parciales en un mecanismo artificial que recoja los aspectos básicos de los fenómenos que imita. Hablamos, pues, del ordenador más que como una finalidad, como una herramienta.
Esto no significa que no exista un ingente número de trabajos cuyos objetivos sean llevar a cabo aplicaciones lingüísticas concretas en ordenador para la ayuda o realización de múltiples tareas. Efectivamente, la ingeniería lingüística está evolucionando rápidamente, y desgraciadamente sin ningún tipo de previsión en cuanto a su impacto social, pero no tenemos que olvidar lo que a la profundización del conocimiento sobre el lenguaje natural y sobre el hombre la lingüística informática y las técnicas de IA pueden aportar.
La comprehensión del conocimiento humano es una tarea larga y difícil. Desde muy diversas disciplinas los investigadores logran aportar trabajos sobre aspectos muy concretos. Este alto grado de especialización no sólo dificulta el que se intercambien hallazgos entre las distintas disciplinas o áreas de estudio, sino que dificulta la expansión de logros incluso dentro de la propia disciplina. Es necesario que los trabajos sobre el conocimiento sean recuperables y contribuyan a construir bases científicas sólidas y probadas aisladamente y en conjunto.
La aproximación hecha en este artículo sobre la IA y el lenguaje ha querido mostrar, entre otras cosas, la posibilidad que ofrecen el uso del ordenador y de ciertas herramientas metodológicas y técnicas para trabajar con sistemas complejos como el conocimiento. La única manera de avanzar en este terreno queda pendiente de la capacidad que tengamos para integrar y aprovechar los trabajos y enfoques que se realicen a través de ciertos principios de representación y mecanismos comunes.
Bernard, G. (1987): «La forme et le fond» en Formalisation des relations prédicatives, París, Collection ERA 642.
Bernard, G. (1984): Esquisse d’un modele linguistique formel de la prédication pour servir a la représentation informatique, París, Tesis doctoral, Universidad París 7.
Bernard, G. & Poswick, F. (eds.) (1990): Les Chemins du Texte, Ginebra-París, Slatkine-Champion.
Boulle, J. (1990): «Opérations et résultats d’opérations», en Les Chemins du Texte, Ginebra-París, Siatkine-Champion.
Feat, J. (1991): DYNAB. Environnement interactif de prototypage et de modélisation; París, Paris 7 collection ERA 642.
Feat J. & Kouloughli D.E. (1988): «The dynamic binding approach to automatic text understanding», en Processing Arabic 3, pp. 13-43, TCMO, Nijmegen University, Holanda.
Grishman, R. (1991): Introducción a la lingüística computacional, Madrid, Visor.
Hendler, J. (1989): «Marker-parsing over microfeatures: toward a hybrid symbolic/connectionist model», Cognitive Science.
Lyons, J. (1977): Semantics, vol. 1 y 2, Cambridge, Cambridge University Press.
Marcos Marín, F. (1992): «Archivos digitales: el Corpus de Referencia de la Lengua Española Contemporánea», Industrias de la lengua, Madrid, S.E.V Centenario.
Minsky, M. (1975): «A Framework for Representing Knowledge», en The Psychology of Computer Vision, ed. Winston (P. H.), Nueva York, Mc Graw Hill Book Comp.
Newell, A. & Simon, H. (1958): «Heuristic problem solving: the next step in operations research», Operations Research, 6, enero-febrero.
Nilsson, N. J. (1987): Principios de Inteligencia Artificial; (trad. de Julio Fernández Biarge) Madrid, Ed. Díaz de Santos.
Pitrat, J. (1988): An artificial intelligence approach to understanding natural language; Londres, North Oxford Academic Publishers Ltd.
Reiss (S. P.), «An Object-oriented Framework for Conceptual Programming», en Research Directions in Object-Oriented Programming, MIT Press, 1987
Relpred (Grupo) (1989): Une méthodologie de construction des représentations en syntaxe énonciative de reconnaissance 1986-1989, París, Paris 7 collección ERA 642, 2 vols.
Relpred (Grupo) (1992): Actas del Primer Seminario de Análisis de Modelos de Informática en Ciencias Humanas; Granada, Univ. de Granada-Univ. Autónoma de Madrid.
Sabah, G. (1988): L’inteligence artificielle et le langage, vol. 1, vol. 2; París, Hermès.
Sabrovsky, E. (1992): «Las máquinas pensantes»; Telos, 30, págs. 15-29.
Shank R. & Abelson R. (1977): Scripts, plans, goals and understanding. An inquiry into human knowledge structures; Hillsdale (Nueva Jersey), Lawrence Erlbaum associates Publishers.
Shank, Roger C. (1982): Dynamic Memory: A theory of reminding and learnig in computers and people; Cambridge, Cambridge U.P.
Winston, P. H. (1977): Artificial Intelligence; Massachusetts, Addison-Wesley Publishing Company.
(1) Para simplificar y permitir la reflexión no tenemos aquí en cuenta las grandes incógnitas que plantea el estudio del lenguaje natural y la creación de formalismos de representaciones y representaciones del conocimiento resultantes. En cualquier caso, los saberes acuñados en estos tres campos son sin duda superiores que los que se han logrado sobre el conocimiento humano, tanto desde el punto de vista físico del cerebro, como del abstracto de la mente.
(2) Para ello nos podemos remitir a Hu, D.: Programer’s Reference Guide to Expert Systems, Indianápolis, Howard W. Sams & Company, 1987.
(3) Feat, J. (1991) DYNAB. Environnement interactif de prototypage et de modélisation, París, Paris 7 collection ERA 642.
(4) Este resumen está inspirado en V. López. «Introducción a las Redes Neuronales»; comunicación del I Coloquio sobre Inteligencia Artificial del Aula Vicente Alexandre, Univ. Autónoma de Madrid-Instituto de Ingeniería del Conocimiento. Madrid, julio de 1990.
(5) Minsky (Marvin). «A Framework for Representing Knowledge», en The
Psychology of Computer Vision, ed. Winston (P.H.). McGraw Hill Book Comp., NY 1975.
(6) Jyn Feat (1991): DYNAB. Environnement interactif de prototypage et de modélisation. París. Paris 7 collection ERA 642.
(7) Ver G. Bernard y P.L. Díez: «Reconocimiento de la sintaxis. Metodología»; en Boulle, J. et al. (G. Relpred) (1992).
(8) Para ver una ejemplificación completa ds esta metodología ver G.Bernard: Esquisse d’un modèle linguistique formel de la prédicación pour servir á la représentación informatique. Thèse de 3è cycle. Université Paris 7, 1984.
(9) G. Bernard, «La Liaison Dynamique», en Bernard G., Poswick F. (eds.): Les Chemins du Texte, Slatkine-Champion, Genève/Paris, 1990, págs. 112-3.
(10) Ver G.Bernard, «Gramática de interdependencias», en Relpred (l992).
(11) En este caso, si la señal es analógica no podrá ser digital y viceversa.
(12) [mode] mono o multivalente, [type] una restricción, [normal] valor por defecto, [public] se puede preguntar por él [prompt] el texto de una pregunta y [means] texto de explicación.
(13) Las posibilidades de uso son muchas, como por ejemplo encontrar el punto de vista correcto para interpretar una palabra en un contexto determinado.
(14) Entre las muchas aplicaciones, un buen ejemplo lo puede constituir en la adquisición de propiedades de una anáfora respecto de su antecedente o consecuente una vez se haya determinado.
(15) Ver J. Feat, Dynab…, 1991. págs. 149-173.
(16) Provocado por un método u objeto dinámico en código lisp que representa por ejemplo.
(17) Los estudios sobre autoorganización se encuentran repartidos en múltiples disciplinas diferentes, desde la neurología o biología hasta la sociología o lingüística. Aquí citamos dos títulos que son más interesantes para los problemas lingüísticos que nos afectan: Dumouchel, P. y Dupuy, J.P.: Colloque de Cerisy. L’autoorganization. De la physique au politique; París, Seuil, 1983; y Bernard (Gilles): «Autoorganisation» en Encyclopédie Philosophique Universelle. Vol. Notions, tomo 1. PUF. París 1990.
(18) ‘Trenzado’ traduce ‘cablage’ en francés concepto que en este sentido ha sido aplicado por Gilles Bernard
Artículo extraído del nº 39 de la revista en papel Telos